
一行、二行、三行,随着数据流畅的打印出来,爬虫技能就算正式入门了。这一刻二两心流,穿胸而过,往昔的丝丝不甘,也如轻烟般燃尽。
对于过往,每每念起的心存不甘,你是否还想着改变。于我而言,在编程领域,一个场景频频闪现,那是毕业前夕,工作去向还未落定,心高气傲的少年,一意孤行要当程序员。
在图书馆阅览室,投递完简历,找了一本 Python 爬虫的工具书,闷头就学。那时夕阳西垂,阳光柔柔洒入,专心致志的背影,一动不动,啃着代码。这本是一个美好的开始,却随着背影歪歪斜斜的爬睡在桌子上落幕。
如果那一刻旁边的背影,恰好回头的话,就会发现页码始终停留在第两页。
毕业后,时而回想当初情景,就燃起一种时断时续劲头,想要彻底拿下这门手艺。每次都像点到为止的泡泡,一碰就破,一吹就飞,难以为继。
到了今年,重新打磨「手艺」,同时又开始学习「开源情报分析」,往昔的不甘又如薄雾般升起。人到中年,难得的是还有一股「与自己较劲的心力」。现下没有当初找工作的技能负担,轻装上阵,重拾内在动机。这次学得很慢、看的很细,在扛过一个个 bug 拳打脚踢后,总算得其门而入。
我喜欢成长的路上刷技能,相比数据分析,爬虫算是高阶的打怪升级。因为网站技术更新很快,爬虫机制实时动态优化,类似攻防对抗,斗个不停。刷完爬虫这门课,加上完成课后练习题、课后作业,大概花了两周的业务时间。每晚写个脚本,爬个网页,看到程序顺畅的执行下来,整天的阴霾都会一扫而空。
作为课程结束的尾声,按照自己掌握的技能(requests + bs4 + selenium + gevent)爬取了近五年当当网 Top500 的畅销书,总计 2500 本书目内容。虽然做了尽可能完备的武装,爬的时候还是心惊胆战,因为当当网的反爬机制很强,生怕惊扰到层层蜘蛛网。
通过爬去的数据分析出,使用 pandas 进行数据清洗,分析出近五年的畅销作家、伯乐出版社,以及蝉联多年的常青藤图书。
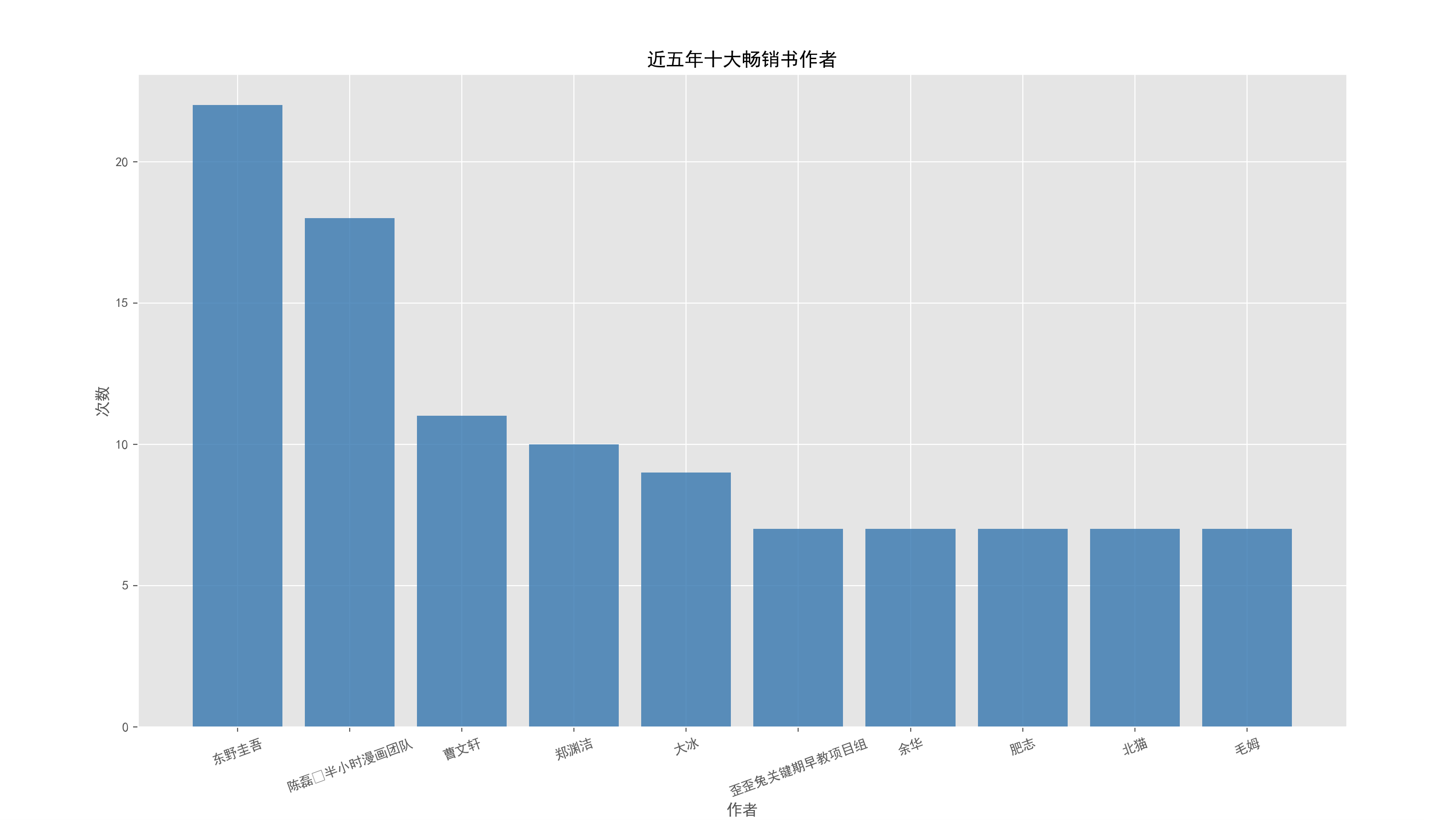

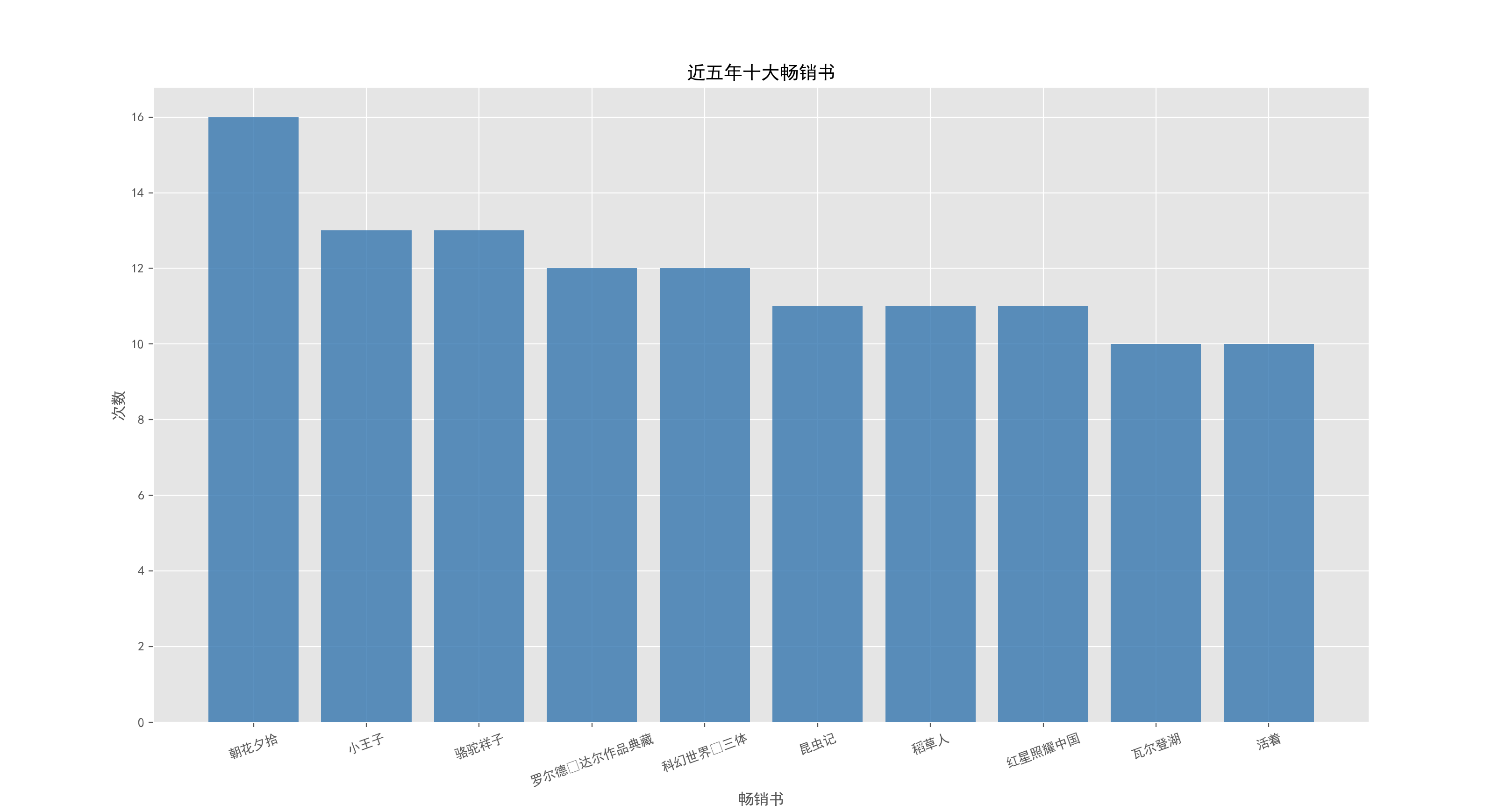
反常识点:
- 数据分析中,书名的数据清洗是个大工程。中英文标识混着用,没有统一的规范,有种当当网负责编辑上架书目信息的人,水平不高,怀疑出自「实习生」之手;
- 十大畅销书作者里面居然有「半小时漫画团队」和「早教项目组」,这个真是大开眼界。东野圭吾在国内的影响力,比我预想的还要大不少;
- 通过「畅销作者」分析出的背后「主力人群」,和「畅销书」背后的人群明显存在一些冲突的地方,还待进一步挖掘。
最后,借用这门课堂的结尾信中的一句话,来结束这篇文章,「逢山开路,遇水架桥,不甘庸碌渡一生的人心怀梦想,梦想即目标。目标即可被分析过程,分析清楚即可被实现。」
我会编程。这太酷了。
ChangLog
- 230307 ZAPP 刷完 python 爬虫的一门课程,写下课程笔记。